
Why Multimodal Emotion Analysis Outperforms Single-Modal Emotion Analysis?
Decades of psychological research show that human emotion is a multi-channel signal, our faces show it, our voices carry it, and our words reason with it.
Research indicates that facial expressions alone are unreliable indicators of emotion, underscoring the importance of integrating multiple cues, such as voice, body posture, and context, for accurate emotional understanding.
Why Single-Modal Emotion Detection Falls Short?
The Limits of Facial Cues
Facial cues tell us a lot.
Facial expressions play a major role in understanding human emotion. (Psychologically) Our faces tend to mirror two main reactions to the world around us: comfort and discomfort.
When we feel comfortable, our facial muscles relax. We smile or laugh easily, our lips look fuller, and our eyes soften. But the moment discomfort sets in, tension appears, the forehead tightens, the chin tucks in, or the eyes narrow. These micro-changes happen instantly, revealing our emotional state even before we say a word.
Still, expressions don’t always mean the same thing for everyone. A furrowed brow can show concentration just as easily as irritation, and a smile might be polite rather than joyful. Without tone of voice or words to accompany it, even clear expressions can be misunderstood.
However, when we rely only on faces, single-channel emotion analysis becomes unreliable.
When people see ambiguous expressions, such as confused or neutral faces, they often assume negative emotions due to a natural bias that appears in the absence of context.
Lower image quality or unclear expressions can further distort interpretation, leading people to project their own expectations rather than accurately perceive someone’s true emotional state.
.jpg?alt=media&token=b623c875-4f80-47dc-a001-886df0be76d2)
3
2
1
Here we go…
.jpg?alt=media&token=f98d83ae-9b65-454c-940f-6b7661d815b3)
Many tools today analyze only facial expressions or emotions, but that approach remains single-modal, focusing on just one source of data. While useful for surface-level detection, it often misses the deeper emotional context that becomes clear only when other cues, such as voice tone, verbal content, and personality traits, are also considered.
When Voice Sends Mixed Signals
Vocal prosody, the emotional tone in our voice shaped by pitch, loudness, rhythm, and speech rate, helps convey how we feel. Yet, when we hear it without other cues, it often leads to confusion.
People can usually recognize anger or sadness from tone alone, but emotions like fear, happiness, or disgust become harder to identify without facial expressions or context. A raised voice might show excitement or irritation. A shaky tone might reflect fear or nervous laughter.
Sarcasm makes things even trickier. When someone says “That was really thoughtful of you” in an exaggerated tone, we can’t always tell if they mean it or not. Once we see their face or gestures, the message becomes clear.
Relying only on vocal prosody causes us to misread emotions. We interpret them far more accurately when we combine voice with visual and contextual signals.
You know, in FRIENDS, when the gang gets locked out? The humor isn't just in the situation; it's in their voices.
Go to Imentiv AI dashboard to see the full audio and transcript analysis , revealing how their angry tone was measured against their simple words.
If we just listen to the audio, their tones show a dramatic spike in anger and intensity. They sound like they're in the middle of a major, high-stakes argument.
But here's what makes it so clever and funny: All that vocal drama is about a simple mix-up over a single word. The entire conflict boils down to a harmless misunderstanding of whether someone asked "Got the keys?" or stated "Got the keys."
This is why we need both sound and words. The heated, dramatic tone makes it feel like a serious conflict, but the actual conversation reveals a classic, relatable comedy of errors. It’s the perfect example of how tone and text work together to create a joke that’s far greater than the sum of its parts.
Why Words Alone Miss the Emotion
Sentiment analysis does a great job of scanning text for tone and intent. It helps spot patterns, pick up keywords, and give a quick read on how someone might be feeling.
But emotions aren’t always that straightforward. Words can hide a lot between the lines.
Sarcasm and Irony: Picture a hotel guest writing, “Loved waiting 45 minutes for check-in, great start to my vacation.” A sentiment model sees “loved” and “great” and tags it as positive. But anyone reading it knows it’s pure frustration.
Tone and Context: Or take, “Sure, whatever you say.” Depending on tone, that’s either agreement or quiet irritation. Same with “Thanks a lot.” , it could mean genuine gratitude or the exact opposite. Without vocal or facial cues, it’s impossible to know.
So yes, sentiment analysis gives a helpful start, but real emotion goes beyond words. To understand how someone truly feels, we need to consider more than just text.
How the Human Brain Really Understands Emotions?
Humans naturally read emotions using more than one signal at a time. The brain processes facial expressions, tone of voice, words, and context together to build a complete emotional picture.
It’s not just about combining signals; it’s a finely tuned process where each cue supports or balances the others. Within the human brain, regions such as the amygdala, insula, and prefrontal cortex synchronize these cues, shaping emotions that we experience with clarity, depth, and accuracy.
When Emotions Spread Between People
Emotions are surprisingly contagious. A laugh, a sigh, or even a subtle tone shift can ripple through a group, shaping how everyone feels. This process, often called emotional contagion, happens naturally because we pick up on multiple signals at once, not just facial expressions.
It’s the mix of cues that makes emotion spread: a smile paired with a warm voice, open posture, or shared moment of excitement. When only one channel is visible, such as a muted video with no sound, the emotional connection weakens. But when all cues come together, people start to mirror one another unconsciously, tuning in emotionally and physically.
Research has shown that this “in-sync” reaction happens more strongly among friends or people who share trust and familiarity. It’s the body’s way of saying, “I feel what you feel.” In real life, and in emotion AI systems, that kind of synchrony is only possible when multiple signals are perceived together.
Multimodal emotion analysis reflects that same principle; it reads emotion the way humans naturally do, through layers of expression that blend into one shared emotional experience.
See how emotion synchrony works , analyze a real video with Imentiv AI , and watch how facial and vocal cues align.
Single vs. Multimodal Emotion Recognition in Today’s AI Space

Many tools in the Emotion AI space focus on a single channel of emotion detection. Some specialize in facial expression recognition, others in voice emotion detection, or even in verbal sentiment analysis. A few extend into physiological signals, capturing data like skin response or brain activity, but they too largely operate within a single modality.
These tools deliver meaningful insights within their domain, yet they capture only one layer of emotional communication. Real human emotion, however, is expressed across multiple cues that work together; what we see, hear, and say often overlap or contrast to form the true emotional picture.
Imentiv AI bridges this gap through a multimodal approach, combining facial, vocal, and verbal analysis with personality insights. By integrating signals from multiple sources, it reflects how humans naturally perceive emotions; contextually, dynamically, and with depth that single-modality tools often miss.
Sometimes, the difference between what people say and what they actually feel is subtle and easy to miss if you’re only looking at one signal. Here’s a simple example that shows why multimodal emotion analysis matters.
Let’s look at an example.
Multimodal Emotion Analysis Example: “This Speech Made the Room Go Silent”
In this 59-second segment from the Golden Globes, Meryl Streep delivers an emotionally charged address highlighting diversity and belonging in Hollywood. While she is the only speaker, the camera captures several audience members; both well-known actors she mentions (Viola Davis, Amy Adams, Ruth Negga, Sarah Jessica Parker, Ryan Gosling, Dev Patel) and other attendees, whose facial reactions offer valuable emotional insight. Using Imentiv AI’s multimodal emotion analysis feature, emotions were analyzed from facial expressions, voice tone, and transcript content to reveal how emotion flows between speaker and audience.
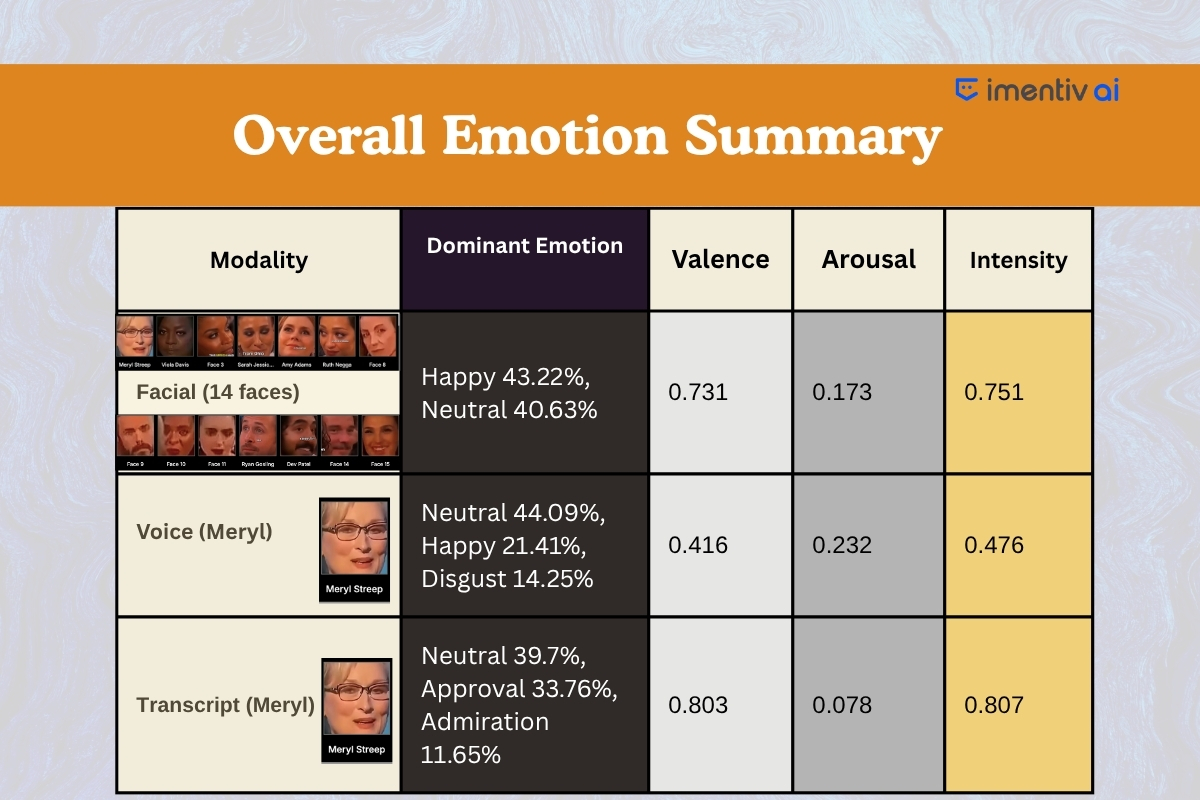
Speaker-Level Analysis (Meryl Streep)
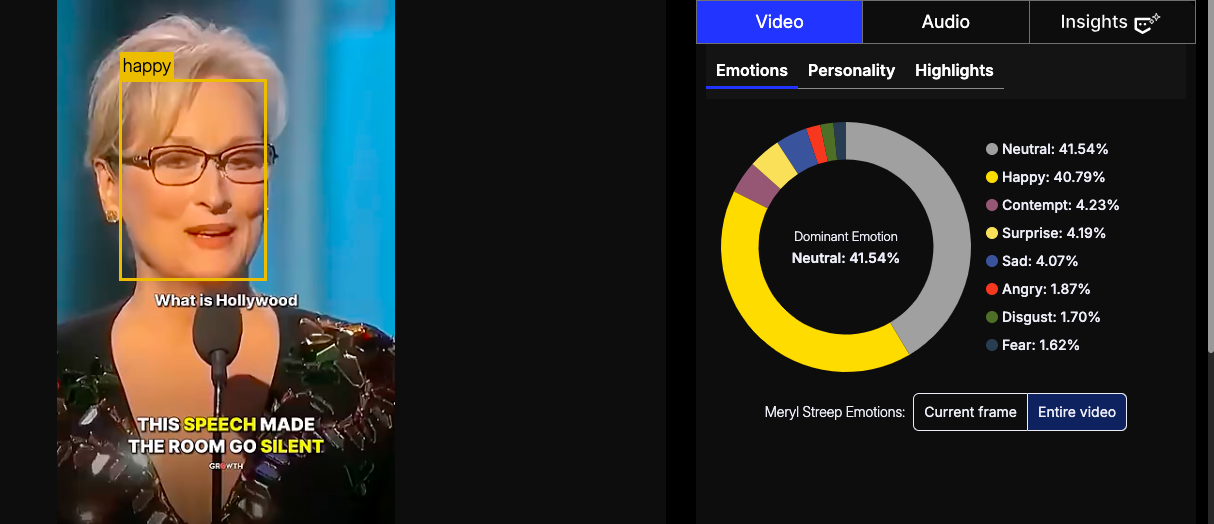
Meryl Streep’s emotional delivery was calm yet intentional. Her facial data shows near-equal levels of neutral (41%) and happy (41%), revealing poise and controlled expressiveness.
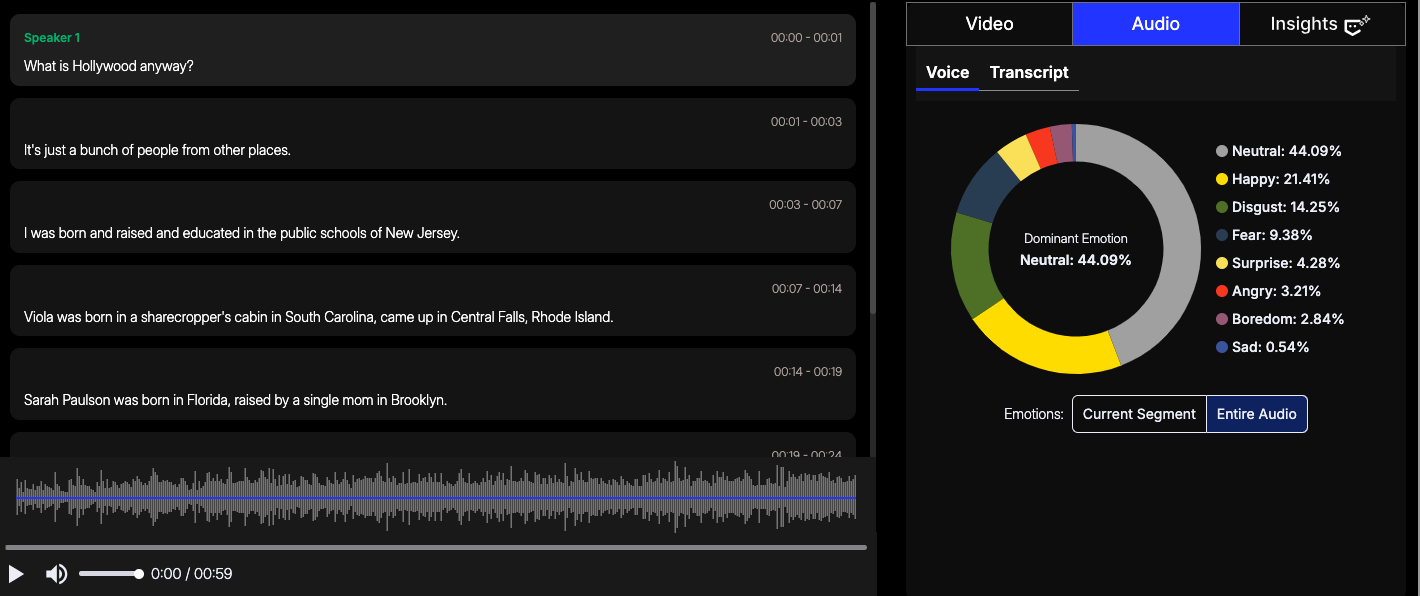
Her vocal profile remains mostly neutral, indicating composure and control throughout the segment. However, subtle traces of disgust and fear are detected, suggesting a deeper emotional engagement.
This mix reflects a psychological pattern of empathetic reflection, a state where the speaker connects emotionally with the subject matter but maintains measured restraint.
Such a tone often emerges when expressing gratitude or acknowledgment with controlled emotion, balancing warmth and empathy with professionalism and composure.
Meryl’s words (transcript emotions) actively express approval and admiration , which psychologically reinforce a sense of belonging and validation among those she addresses.
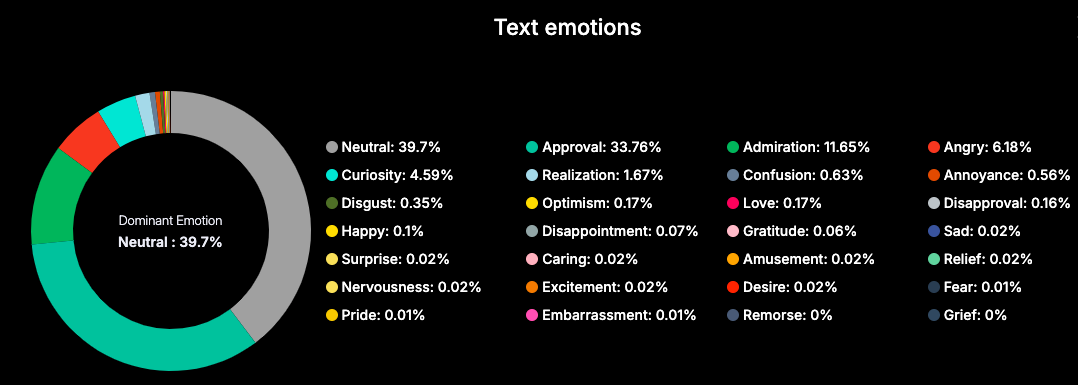
This verbal tone mirrors a pro-social emotional pattern often seen in affirming communication, where the speaker’s emotional expression nurtures inclusivity and strengthens collective emotional resonance.
Together, these patterns reflect emotional regulation, where sincerity and conviction emerge through composure rather than intensity, exemplifying persuasive emotional leadership.
Audience-Level Emotional Response
The visible audience showed a broad emotional spectrum, with reactions shifting subtly across individuals.
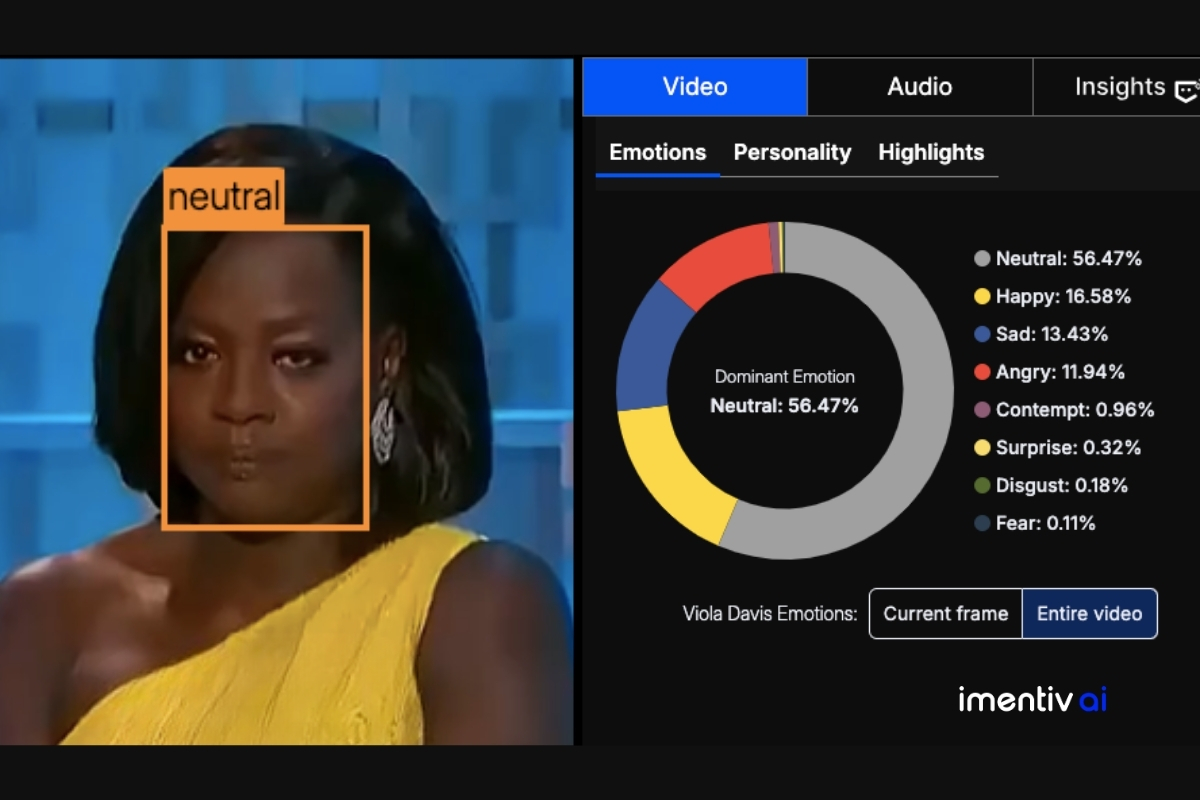
Viola Davis maintained composure ( neutral 56% ) with undercurrents of sadness and anger , reflecting deep emotional resonance with the topic’s relevance.
Sarah Jessica Parker balanced neutral and happy expressions, suggesting empathetic attention.
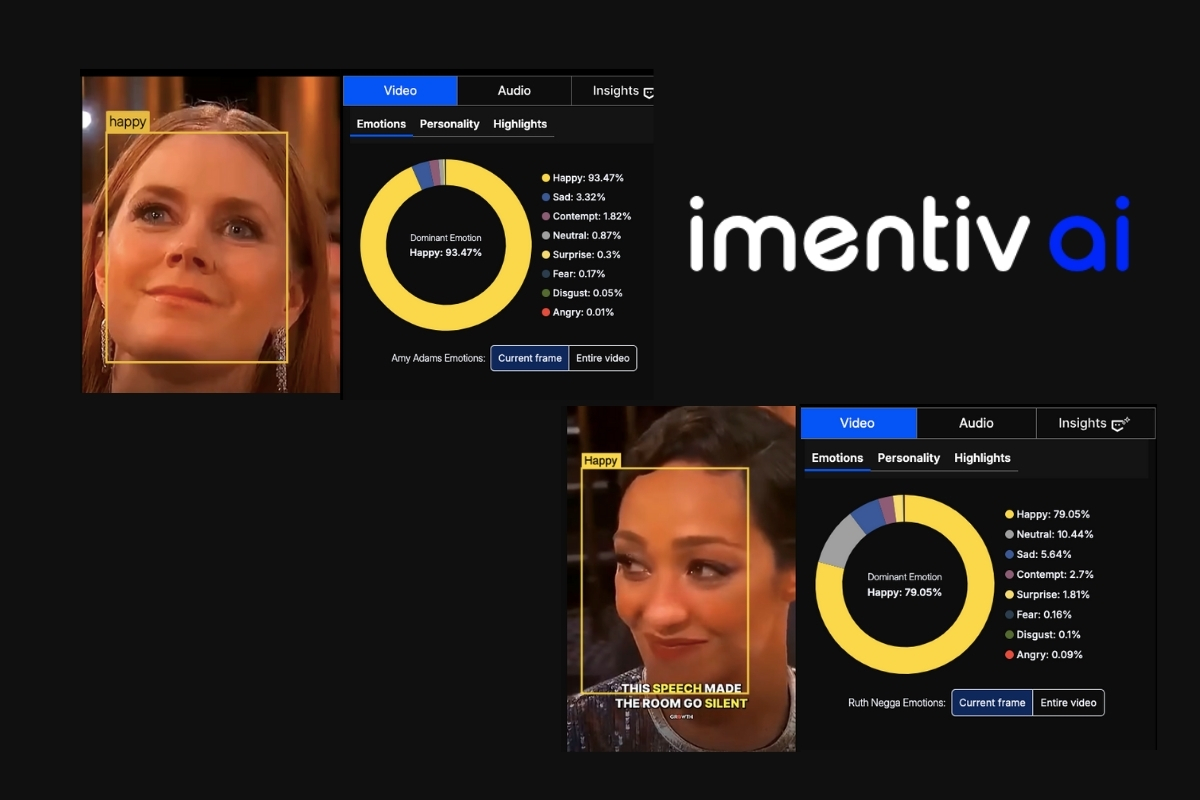
Amy Adams and Ruth Negga displayed high happiness levels (above 79–90%), signaling emotional warmth and approval.
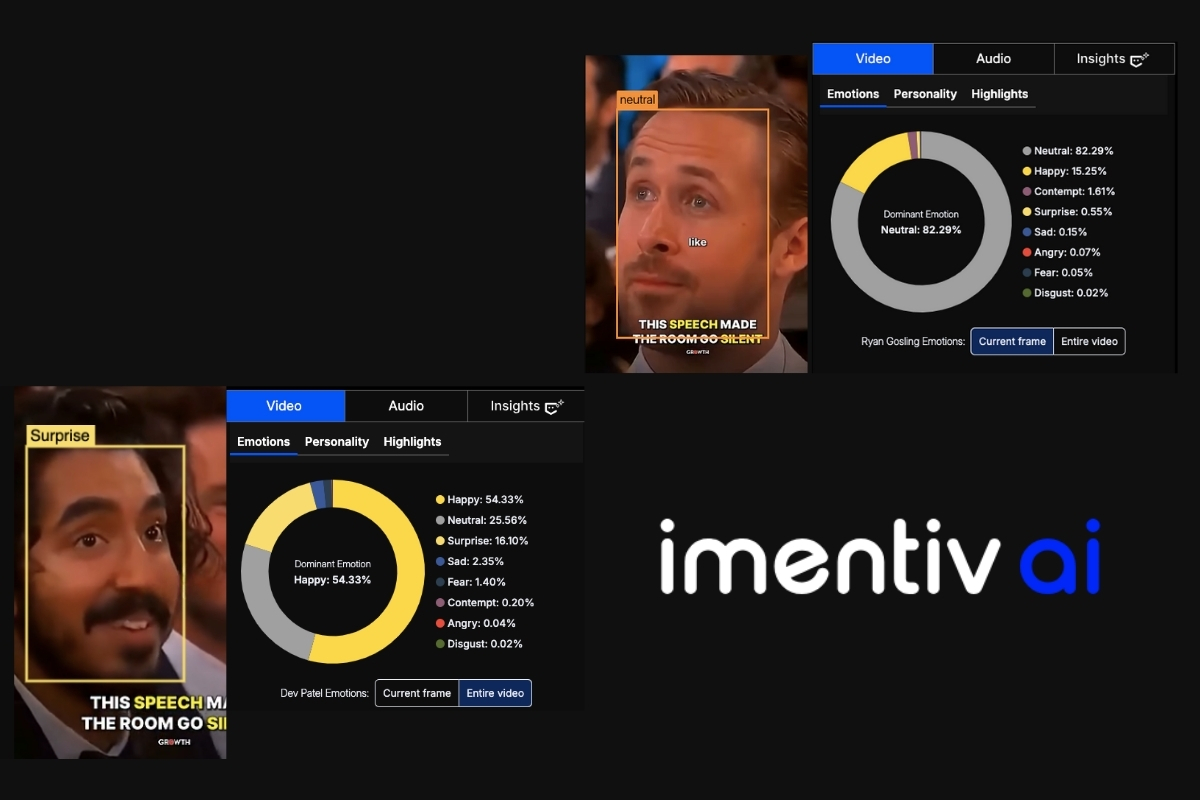
Ryan Gosling and Dev Patel showed mixed happy-neutral expressions, with Dev Patel’s data also revealing surprise (16%) , a brief spontaneous emotional lift, common during shared recognition moments.
Other audience faces (3, 8, 9, 10, 11, 14, 15) reflected neutral and happy combinations, with some showing mild sadness or surprise . Psychologically, this indicates reflective empathy , a quiet, inward response rather than overt excitement.
Collectively, the audience’s high valence (0.73) and moderate intensity (0.75) point to positive emotional synchronization , a shared but controlled resonance aligning with the speaker’s tone.
Cross-Modal Interpretation
The multimodal data reveal nuanced but coherent emotional congruence between Meryl Streep and her audience.
Facial layer : calm composure balanced with subtle warmth, reflecting empathy through controlled expression. Vocal layer : moral conviction expressed with restraint, maintaining composure while conveying depth. Textual layer : verbal cues of approval and admiration, establishing cognitive and emotional alignment.
This tri-layer pattern reflects emotional alignment, where Meryl’s calm control and the audience’s quiet empathy create a connection without overt display.
This example highlights the precision of Imentiv AI’s multimodal emotion analysis feature in decoding emotional dynamics that go beyond visible or audible reactions. By integrating facial, vocal, and textual emotion insights, the analysis captures how emotions are felt, shared, and regulated across speaker–audience interactions.
Even in moments described as “the room went silent,” the data demonstrates that silence itself can carry strong emotional weight, signifying moral resonance, empathy, and shared understanding, not detachment.
Discover More with Insights by Imentiv AI
While the multimodal analysis shows how emotions change across facial, vocal, and textual layers, Imentiv AI’s Insights feature lets users explore the media in their own way — by asking questions that match their needs and goals.
With Insights , users interact directly with the analyzed video to get clear, data-based answers . They use it not only to understand emotions but also to make better decisions, evaluate responses, or take action using emotional evidence .
Users can, for example, ask:
- “Did Meryl’s calm tone and expression keep people emotionally connected till the end?”
- “Which part of the speech drew the strongest empathetic reaction from the crowd?”
- “Did the silence in the room reflect tension or shared understanding?”
Beyond these, users can ask any question they want — whether they need an unbiased emotional interpretation or supporting data before drawing conclusions.
Insights builds each answer using Imentiv AI’s multimodal emotion data, combining facial, vocal, and textual analysis across all people involved. While this example shows how it works with video, Insights is also available across Imentiv AI’s audio, image, and text analysis products .
Even before users type a question, predefined queries appear to point out key emotional moments, helping them explore deeper findings instantly.
By turning emotion analysis into an interactive, evidence-driven experience , Insights helps every user see the emotional truth within their media — with more clarity, depth, and confidence.
Let’s look at another example that highlights the need for multimodal emotion analysis, where understanding emotions goes beyond just one signal.
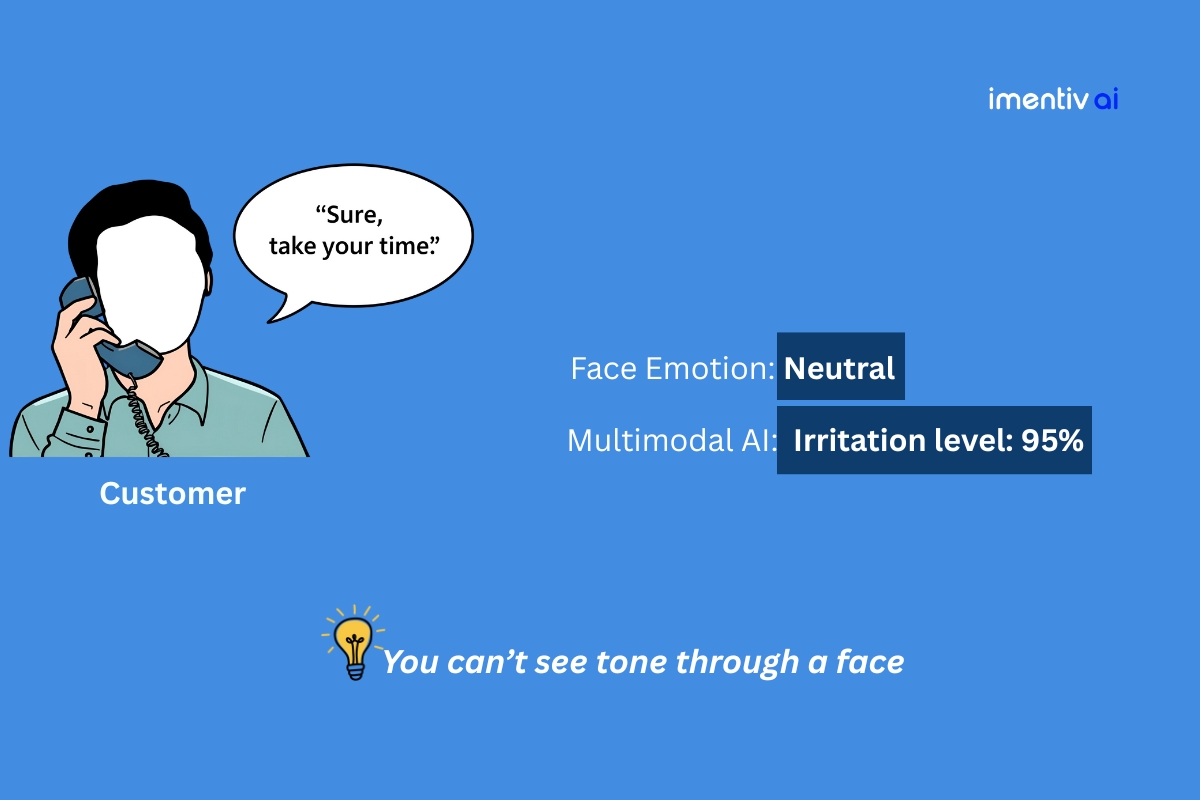
Imagine a customer support call. The agent asks, "How was your experience with our service today?" The customer replies:
Text: "It was fine."
Based on text analysis alone, this is a neutral or even slightly positive response. The ticket gets closed, and the company moves on.
But what if you could hear the customer's voice? A sharp, clipped tone and a sarcastic drawl on the word "fine" instantly change the meaning from neutral to deeply dissatisfied.
Now, imagine you also had a video of this interaction. The customer rolls their eyes, their lips are tight, and they look away in frustration. The full picture is now undeniable: this customer is not "fine" at all; they are on the verge of churning.
A single-modality tool would have missed this entirely. It’s this critical gap between what is said and what is truly felt that costs businesses customer loyalty and revenue.
Emotions don’t live in just one place; they’re shared through our faces, voices, and words all at once. When these emotional signals come together, we get a truer sense of what someone really feels, not just what they show. At Imentiv AI, that’s the goal: to make technology understand emotion with the same depth, context, and balance that humans do.
Our Perspective
At Imentiv AI, we know that no two people express emotions in the same way, and that’s what makes emotion analysis exciting and meaningful. Our Emotion AI system looks at faces, voices, and words together to form a fuller, more balanced view of what someone feels. We continuously refine our datasets and models to keep improving accuracy and inclusiveness. And whenever deeper understanding is needed, our experts, from psychology and AI, work closely with users and partners to interpret emotional insights with the right context and care.
Ready to decode emotion like humans do? Start your multimodal emotion analysis with Imentiv AI today .
Disclaimer: Imentiv AI is a tool to assist human understanding. All findings are derived from observable cues and are intended to support, not replace, human evaluation or judgment. It does not claim to access or interpret an individual’s inner thoughts or intentions.