Unraveling the Mystery of Teacher-Student Models: A Deep Dive into Knowledge Distillation
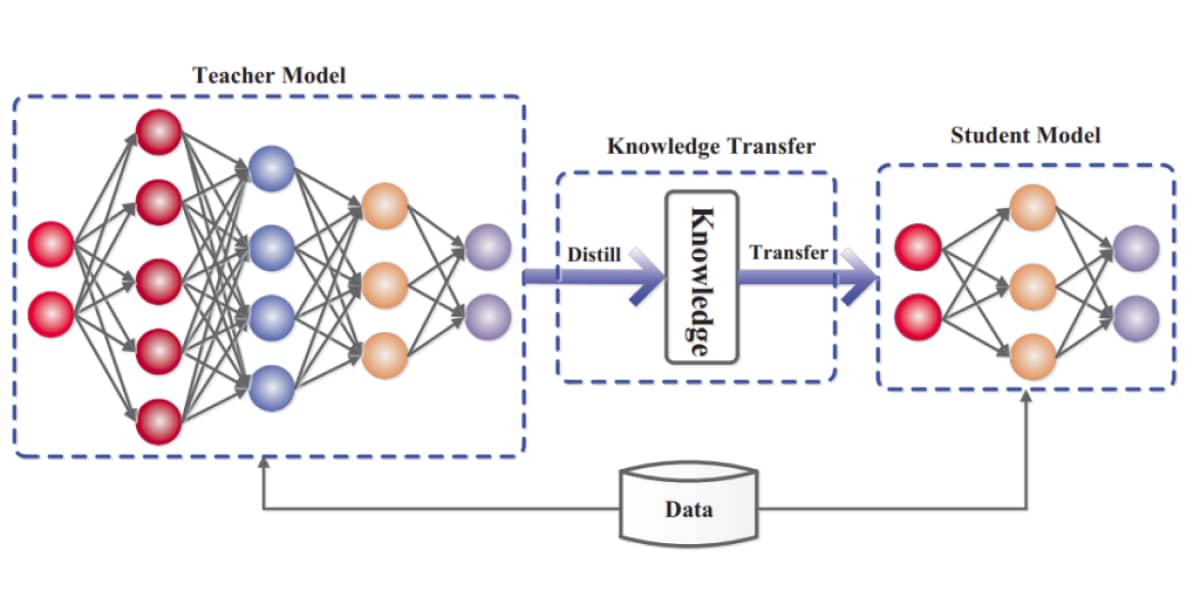
In machine learning, teacher-student models have emerged as a powerful tool for improving the efficiency and effectiveness of deep neural networks. At the heart of this approach lies the concept of knowledge distillation, a technique that enables the transfer of knowledge from a well-trained, larger model, known as the teacher, to a smaller, less complex model, referred to as the student.
The Rationale Behind Teacher-Student Models
The primary motivation behind teacher-student models stems from the challenges associated with large-scale deep neural networks. While these models exhibit remarkable performance in various tasks, their complexity often leads to computational burdens and memory constraints, making them impractical for deployment on resource-limited devices.
Teacher-student models address this issue by leveraging the knowledge and expertise of a larger model to train a smaller, more efficient one. The student model learns from the teacher's predictions, mimicking its behavior and refining its own understanding of the data. This process leads to a smaller, more efficient model that can achieve performance comparable to or even surpassing that of the teacher.
Knowledge Distillation: The Mechanism Behind Teacher-Student Models
Knowledge distillation is the key mechanism that enables the transfer of knowledge from teacher to student. It involves several steps:
- Teacher Model Training: The first step involves training the teacher model on a large dataset of labeled data. This model serves as the foundation of knowledge, capturing intricate patterns and relationships within the data.
- Intermediate Representations: During training, the student model not only learns from the teacher's final predictions but also from its intermediate representations. These intermediate representations, often referred to as activations or feature maps, provide valuable insights into the teacher's decision-making process.
- Soft Targets: Instead of using hard labels (e.g., 0 or 1) to train the student, knowledge distillation employs soft targets. These soft targets, often represented as probabilities, reflect the teacher's confidence in its predictions, allowing the student to learn from both the correct and incorrect predictions of the teacher.
- Temperature Parameter: The temperature parameter controls the softness of the teacher's predictions, influencing the student's learning process. A higher temperature leads to softer predictions, allowing the student to learn from a more diverse range of possible outcomes.
Datasets for Semi-Supervised Learning in Image Classification
In the field of machine learning, semi-supervised learning has emerged as a promising approach for improving the performance of image classification models, particularly when only a small amount of labeled data is available. The author's work on semi-supervised learning employed two large-scale datasets: YFCC-100M and IG-1B-Targeted.
YFCC-100M: A Rich Source of Publicly Available Images
The YFCC-100M dataset, derived from the Flickr website, comprises an impressive collection of approximately 90 million images. This dataset offers a wealth of data for training image classification models, with each image accompanied by associated tags that provide additional context and information. To ensure the integrity of the dataset, the author carefully removed duplicates, ensuring that the training process is based on a clean and reliable source of data.
IG-1B-Targeted: Harnessing Social Media for Large-Scale Data Collection
Inspired by previous work, the author curated the IG-1B-Targeted dataset, consisting of a remarkable 1 billion public images. These images were gathered from a popular social media platform and were associated with relevant hashtags. The selection criteria for the dataset involved identifying images tagged with at least one of the 1500 hashtags linked to the 1000 classes in the ImageNet-1k dataset. This approach ensured that the dataset remained relevant to the task of image classification.
ImageNet: The Standard Labeled Dataset
For the labeled set of data in the experiments, the author employed the widely recognized ImageNet dataset. This dataset encompasses 1000 distinct classes, making it a valuable benchmark for evaluating the performance of image classification models.
The combination of these datasets, with their diverse sources and varying sizes, provided a comprehensive foundation for the author's research on semi-supervised learning in image classification. The large-scale nature of the datasets allowed for extensive training and exploration of different semi-supervised learning techniques, while the labeled set from ImageNet facilitated the evaluation of the model's performance.
Leveraging Unlabeled Data: A Semi-Supervised Approach to Image Classification with Billion-Scale Data
In the realm of machine learning, the availability of labeled data is often a limiting factor. Acquiring labeled data can be a time-consuming and expensive process, especially for large-scale tasks such as image classification. To address this challenge, researchers have explored semi-supervised learning techniques, which utilize both labeled and unlabeled data to improve model performance.
In [1], the author introduced a novel semi-supervised approach for image classification that leverages billions of unlabeled images. Their method employs a teacher-student paradigm, where a teacher model trained on labeled data guides the learning of a smaller student model. This approach enables the student model to benefit from the knowledge of the teacher, even with a limited amount of labeled data.
The author's pipeline involves several key steps:
- Teacher Model Training: A teacher model is trained on a labeled dataset, capturing intricate patterns and relationships within the data.
- Data Selection and Labeling: The unlabeled dataset is filtered using the teacher model to select high-quality examples and assign labels.
- Student Model Training: A student model is trained on the newly labeled dataset, utilizing the knowledge distilled from the teacher model.
- Fine-Tuning: The student model is fine-tuned on the original labeled dataset for further refinement.
To evaluate the effectiveness of their approach, the author conducted extensive experiments on the ImageNet dataset. Their results demonstrate that their semi-supervised method outperforms traditional fully supervised learning, achieving significant accuracy improvements for various model capacities.
The author's work highlights the potential of semi-supervised learning in making better use of unlabeled data, particularly for large-scale tasks. Their approach provides a valuable tool for researchers and practitioners working in the field of image classification.
In addition to the performance gains, the author's approach offers several advantages:
- Reduced Labeling Effort: By utilizing unlabeled data, the need for manual labeling is significantly reduced.
- Improved Efficiency: The student model, being smaller and less complex than the teacher model, reduces computational costs and memory requirements.
- Enhanced Generalization: Exposure to a vast amount of unlabeled data can enhance the model's ability to generalize to unseen data distributions.
The author's work has opened up new avenues for research in semi-supervised learning, paving the way for more efficient and effective models that can harness the power of massive unlabeled datasets.
Model Selection:
The authors used a variety of models for both teacher and student networks. The teacher model is responsible for training the student model, so it needs to be a more complex and powerful model. The student model, on the other hand, needs to be smaller and simpler so that it can run efficiently on devices with limited resources.
Training Approach:
The models were trained using a technique called stochastic gradient descent (SGD). SGD is a common optimization algorithm used in machine learning. It works by iteratively updating the model's parameters in a direction that reduces the loss function. The loss function is a measure of how well the model is performing.
Learning Rate Schedule:
The learning rate is a parameter that controls how much the model's parameters are updated each iteration. The learning rate needs to be carefully chosen, as too high of a learning rate can cause the model to diverge, while too low of a learning rate can cause the model to converge too slowly.
Default Parameters:
The default parameters are a set of values that were chosen to be reasonable for the task of image classification. These parameters can be adjusted depending on the specific task and dataset.
Unlabeled Dataset:
The unlabeled dataset is a collection of images that do not have any labels. The authors used a dataset called YFCC100M, which contains 90 million images.
Experiments and Analysis:
The authors conducted a number of experiments to evaluate their approach. They compared their approach to traditional fully supervised learning, and they also studied the effect of various parameters on the performance of their model. The results of their experiments show that their approach is effective at improving the performance of image classification models, even when only a small amount of labeled data is available.
Applications of the Teacher-student Approach
Teacher-student models are a type of knowledge distillation technique that transfers knowledge from a larger, more accurate model, known as the teacher, to a smaller, less complex model, referred to as the student. This process allows the student model to learn from the teacher's expertise and achieve performance comparable to or even surpassing that of the teacher.
Teacher-student models have been successfully applied to a variety of tasks in different domains and application areas, including:
Image Classification:
Teacher-student models have been used to achieve state-of-the-art results on image classification benchmarks such as ImageNet and CIFAR-10. By learning from the teacher model's predictions and intermediate representations, student models can achieve similar accuracy while being significantly smaller and more efficient.
Natural Language Processing (NLP):
Teacher-student models have been employed in various NLP tasks, including machine translation, sentiment analysis, and text summarization. In machine translation, teacher-student models have been shown to improve the fluency and accuracy of translations compared to traditional methods. In sentiment analysis, student models trained with teacher models can effectively classify the sentiment of text with improved accuracy. In text summarization, teacher-student models can generate concise and informative summaries of lengthy texts.
Speech Recognition:
Teacher-student models have also been applied to enhance the performance and efficiency of speech recognition systems. By distilling knowledge from large, pre-trained teacher models, student models can improve word error rates and reduce computational requirements. This makes them suitable for real-time speech recognition applications.
Other Applications:
Beyond these primary areas, teacher-student models have also been explored in other domains such as:
- Recommendation Systems: Teacher-student models can be used to improve the accuracy and efficiency of recommendation systems by learning from the preferences of users and experts.
- Medical Diagnosis: Teacher-student models can be employed to assist in medical diagnosis by learning from the expertise of experienced physicians and medical data.
- Anomaly Detection: Teacher-student models can be applied to detect anomalies in data streams by learning patterns from normal data and identifying deviations from those patterns.
The applications of teacher-student models are continuously expanding as researchers explore new ways to transfer knowledge between models and improve the performance of machine learning systems in various domains.
Reference
[1] Yalniz, I. Zeki, et al. "Billion-scale semi-supervised learning for image classification." arXiv preprint arXiv:1905.00546 (2019).
.jpg?alt=media&token=eb82a714-150c-4352-aab6-e3e0e8099e0c&w=1920&q=75)

%201.jpg?alt=media&token=ceda4451-752f-4b66-9df7-a0c9df0d00fa&w=1920&q=75)
%20(1).jpg?alt=media&token=670e5e17-a6cc-4806-85be-57a831de05de&w=1920&q=75)