
Speaker Diarization: From Conversations to Clarity
Speaker diarization is the process of automatically identifying and distinguishing “who spoke when” in an audio or video recording. It’s turning one big conversation into labeled parts, so you know exactly who said what.
Imentiv AI’s Speech Emotion Recognition technology includes speaker diarization to separate and analyze individual voices in any group audio, meetings, calls, interviews, or podcasts. Our platform takes Speaker Diarization further, pairing it with emotion analysis. That way, you don’t just see what was said, but also how it was said.
You can :
- Identify and segment each speaker
- Detect emotions for each voice separately
- Understand emotional flow across group conversations
- Get precise, time-stamped emotion data
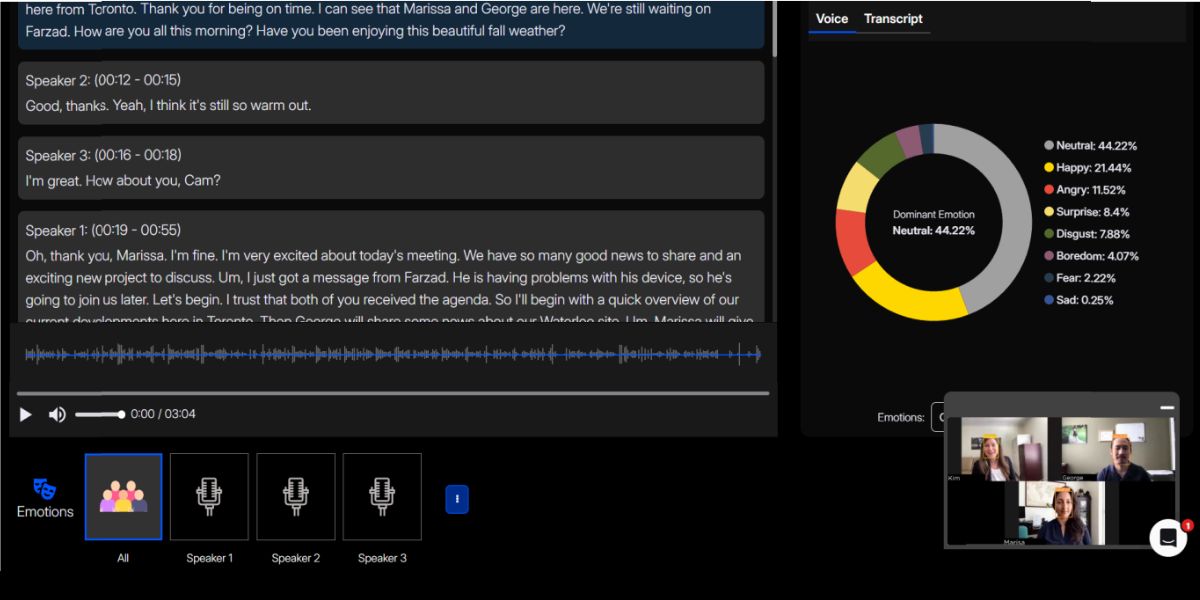
Instead of reading through long, unstructured transcripts or guessing which part belongs to whom, Speaker Diarization helps you visualize the flow of conversation speaker by speaker, segment by segment.
How it Works in Imentiv AI
When you upload your file (audio or video), Imentiv AI analyzes emotions using voice patterns, pitch, tone, speaking rhythm, and frequency features. Simultaneously, it automatically segments the audio by identifying and separating each speaker, labeled as Speaker 1, Speaker 2, and so on, and identifies emotions in each segment. You also have the option to rename the speakers accordingly.
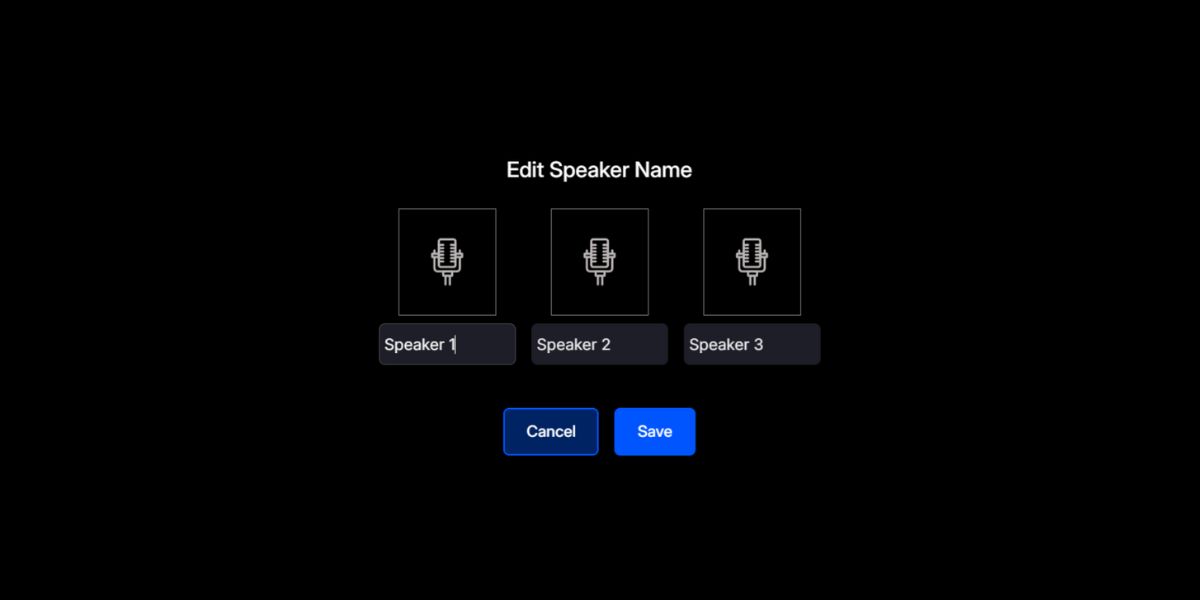
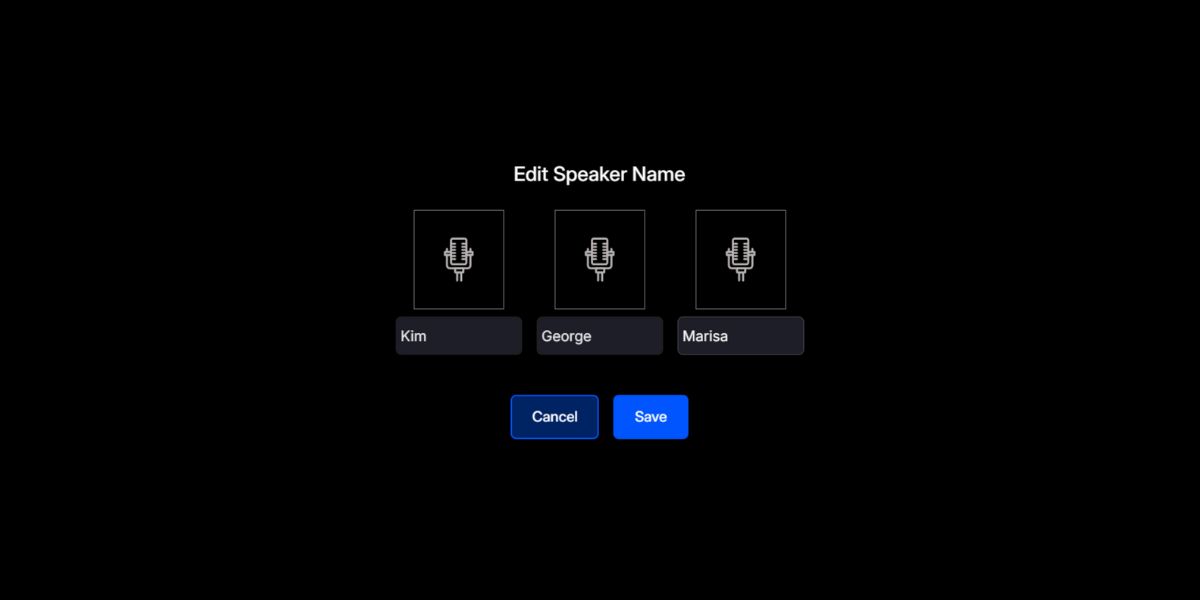
Our platform also aligns the emotional timeline for each speaker, providing a multi-layered view of the conversation. You can then explore each speaker's valence and arousal data through our dynamic emotion graph, helping you see whether the speaker's tone is calm or excited and positive or negative.
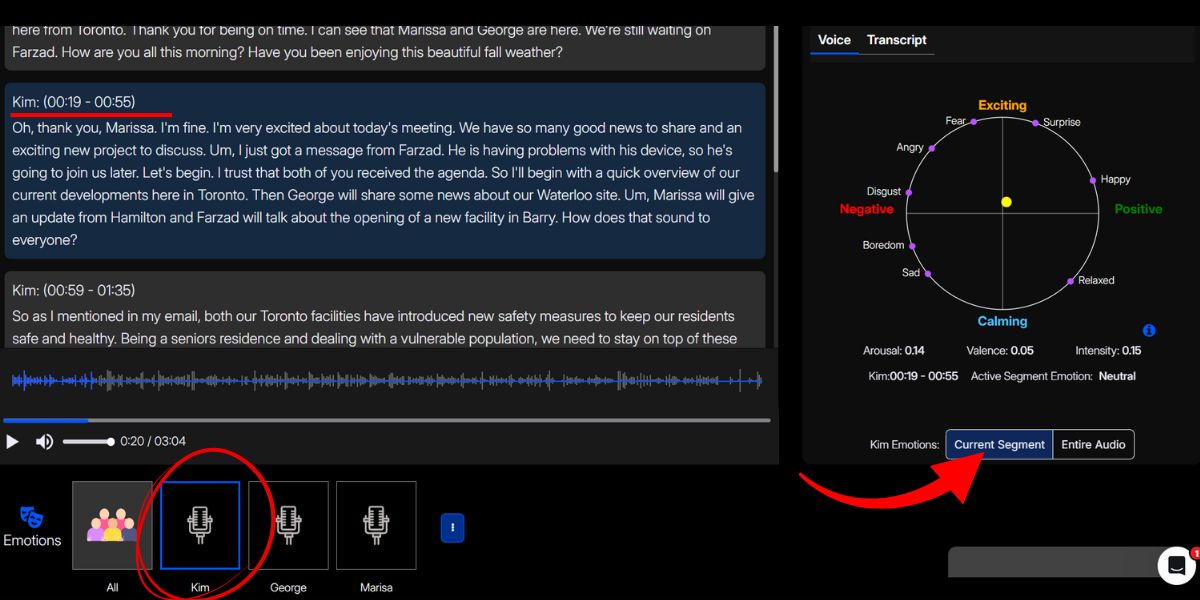
At the same time, you can click on the ‘ Entire Audio’ next to the ‘Current Segment’ to explore the speaker's exhibited emotions in a static Emotion Graph.
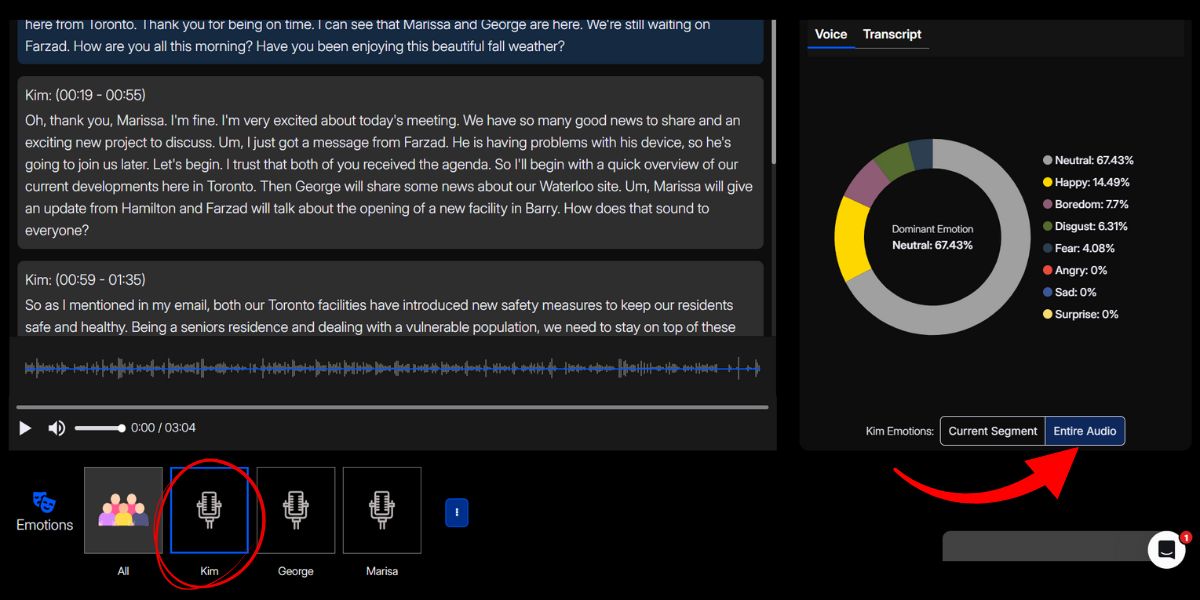
With Imentiv AI’s Speaker Diarization, every conversation becomes clear, structured, and emotionally insightful. What was once overlapping dialogue is now transformed into a detailed, speaker-wise emotional narrative, making meetings, interviews, and discussions easier to interpret and act upon.